Learning linear state-space models with sparse system matrices
{kind=link}
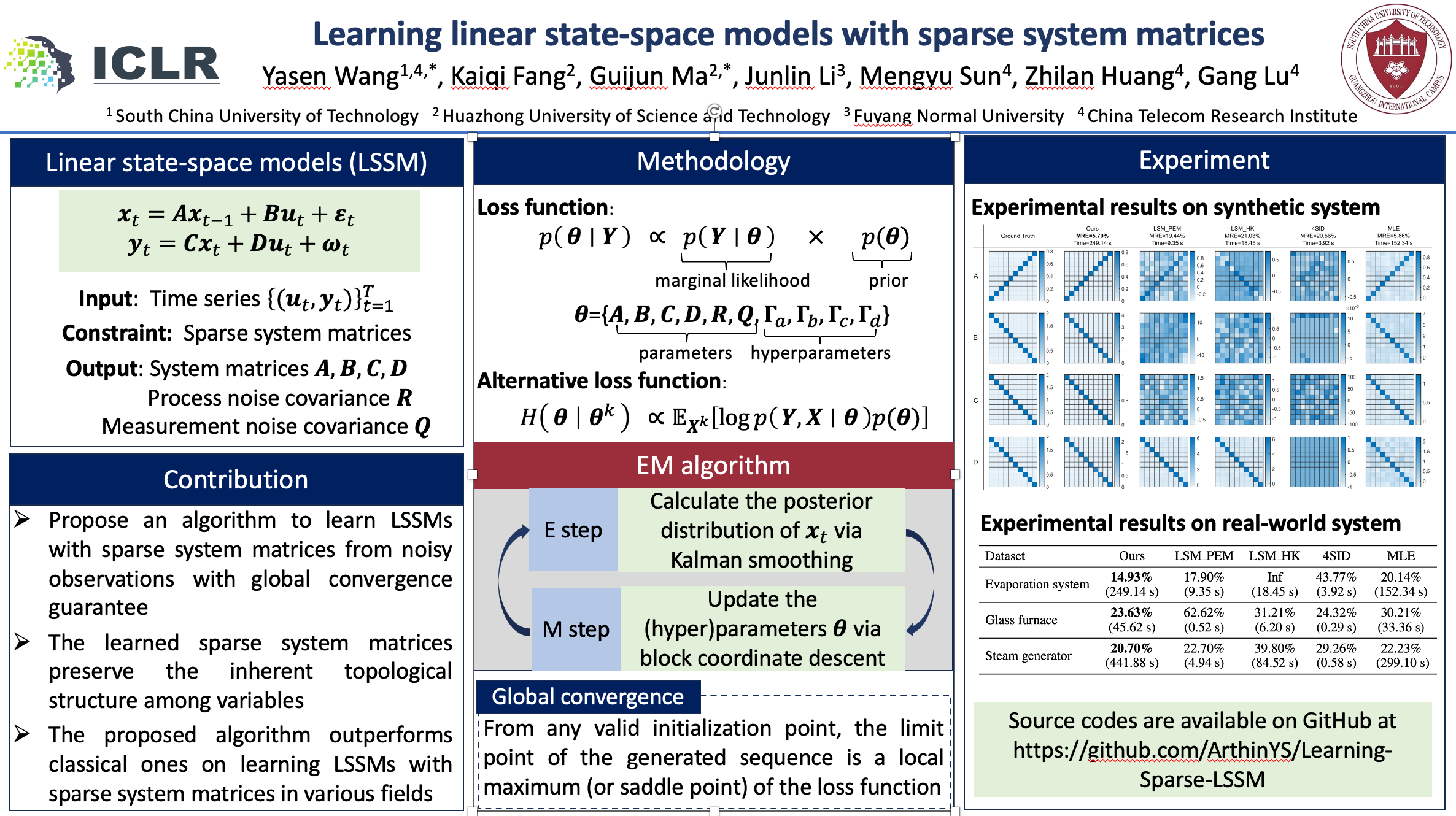
Abstract
Due to tractable analysis and control, linear state-space models (LSSMs) provide a fundamental mathematical tool for time-series data modeling in various disciplines. In particular, many LSSMs have sparse system matrices because interactions among variables are limited or only a few significant relationships exist. However, current learning algorithms for LSSMs lack the ability to learn system matrices with the sparsity constraint due to the similarity transformation. To address this issue, we impose sparsity-promoting priors on system matrices to balance modeling error and model complexity. By taking hidden states of LSSMs as latent variables, we then explore the expectation-maximization (EM) algorithm to derive a maximum a posteriori (MAP) estimate of both hidden states and system matrices from noisy observations. Based on the Global Convergence Theorem, we further demonstrate that the proposed learning algorithm yields a sequence converging to a local maximum or saddle point of the joint posterior distribution. Finally, experimental results on simulation and real-world problems illustrate that the proposed algorithm can preserve the inherent topological structure among variables and significantly improve prediction accuracy over classical learning algorithms.