Visual Compositional Tuning
{kind=link}
Abstract
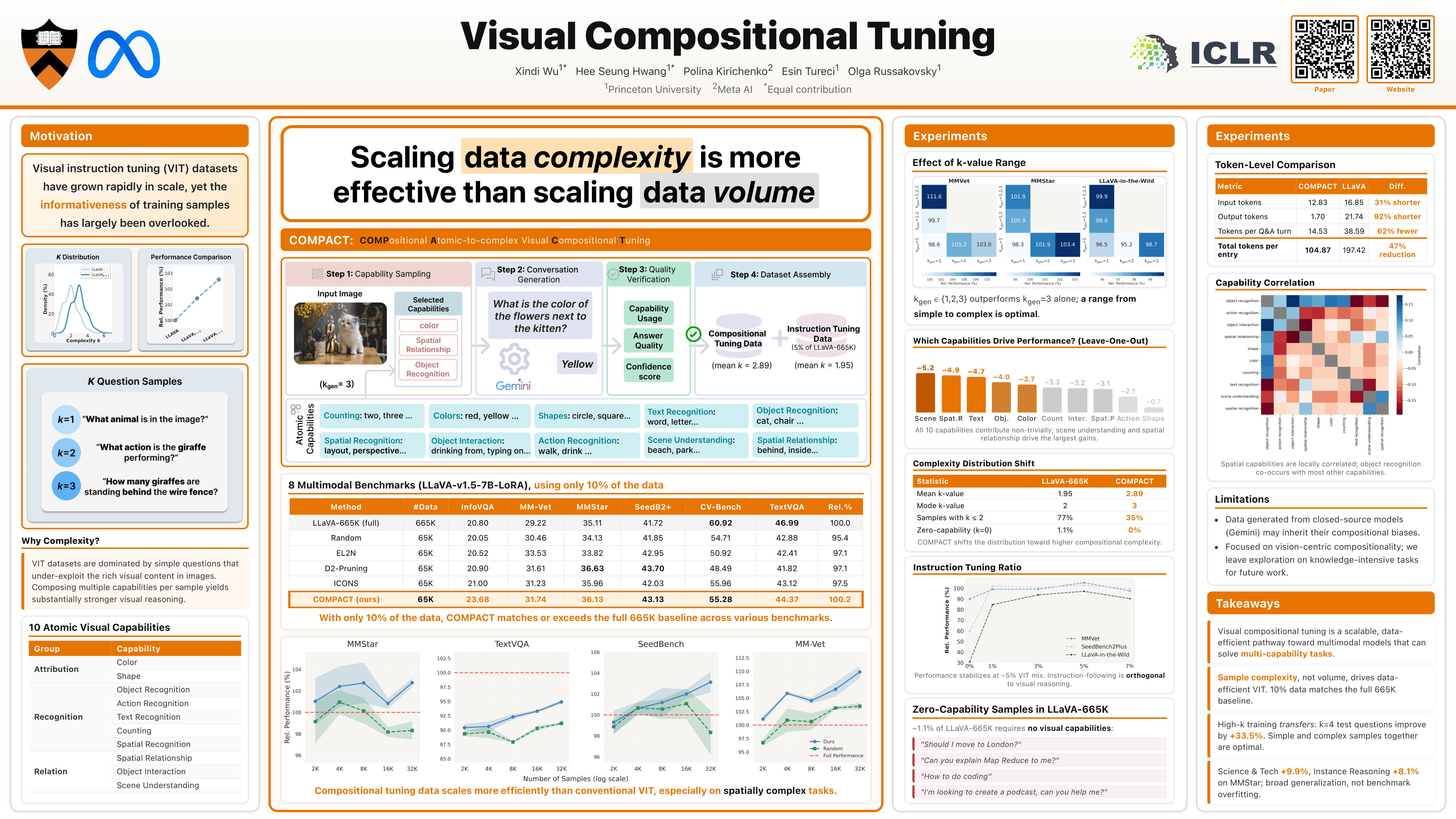
Visual instruction tuning (VIT) datasets have grown rapidly in scale, yet the informativeness of individual training samples has largely been overlooked. Recent dataset selection methods have shown that a small fraction of such datasets enriched with informative samples can lead to efficient finetuning of Multimodal Large Language Models. In this work, we explore the impact of sample complexity on informative data curation and introduce COMPACT (COMPositional Atomic-to-complex Visual Compositional Tuning), a visual compositional tuning data recipe that scales training sample complexity by combining multiple atomic visual capabilities in a single training example. Concretely, we synthesize rich and informative text questions for each image, allowing us to significantly reduce the number of training examples required for effective visual instruction tuning. COMPACT demonstrates superior data efficiency compared to existing data reduction methods. When applied to the LLAVA-665K VIT dataset, COMPACT reduces the data budget by 90% while still achieving 100.2% of the full VIT performance (compared to only 97.5% by the state-of-the-art method) across eight multimodal benchmarks. Further, training on the COMPACT data outperforms training on the full-scale VIT data on particularly complex benchmarks such as MM-Vet (+8.6%) and MMStar (+2.9%). COMPACT offers a scalable and efficient synthetic data generation recipe to improve on vision-language tasks.