Enhancing Protein Language Model with Structure-based Encoder and Pre-training
in
Workshop: Machine Learning for Drug Discovery (MLDD)
{kind=link}
Abstract
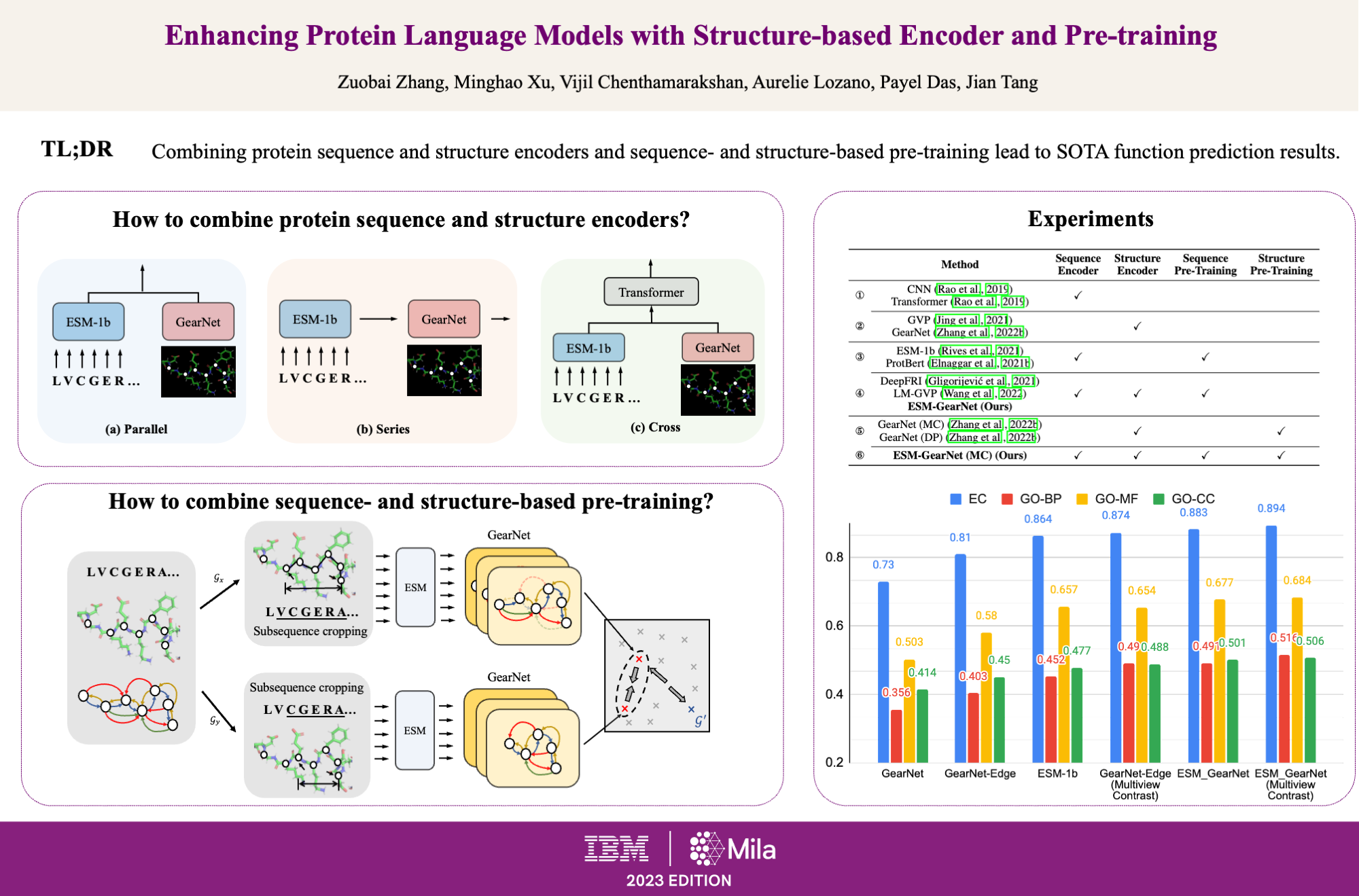
Protein language models (PLMs) pre-trained on large-scale protein sequence corpora have achieved impressive performance on various downstream protein understanding tasks. Despite the ability to implicitly capture inter-residue contact information, transformer-based PLMs cannot encode protein structures explicitly for better structure-aware protein representations. Besides, the power of pre-training on available protein structures has not been explored for improving these PLMs, though structures are important to determine functions. To tackle these limitations, in this work, we enhance the PLM with structure-based encoder and pre-training. We first explore feasible model architectures to combine the advantages of a state-of-the-art PLM (i.e., ESM-1b) and a state-of-the-art protein structure encoder (i.e., GearNet). We empirically verify the ESM-GearNet that connects two encoders in a series way as the most effective combination model. To further improve the effectiveness of ESM-GearNet, we pre-train it on massive unlabeled protein structures with contrastive learning, which aligns representations of co-occurring subsequences so as to capture their biological correlation. Extensive experiments on EC and GO protein function prediction benchmarks demonstrate the superiority of ESM-GearNet over previous PLMs and structure encoders, and clear performance gains are further achieved by structure-based pre-training upon ESM-GearNet. The source code will be made public upon acceptance.