Accelerating Neural Self-Improvement via Bootstrapping
in
Workshop: Mathematical and Empirical Understanding of Foundation Models (ME-FoMo)
{kind=link}
Abstract
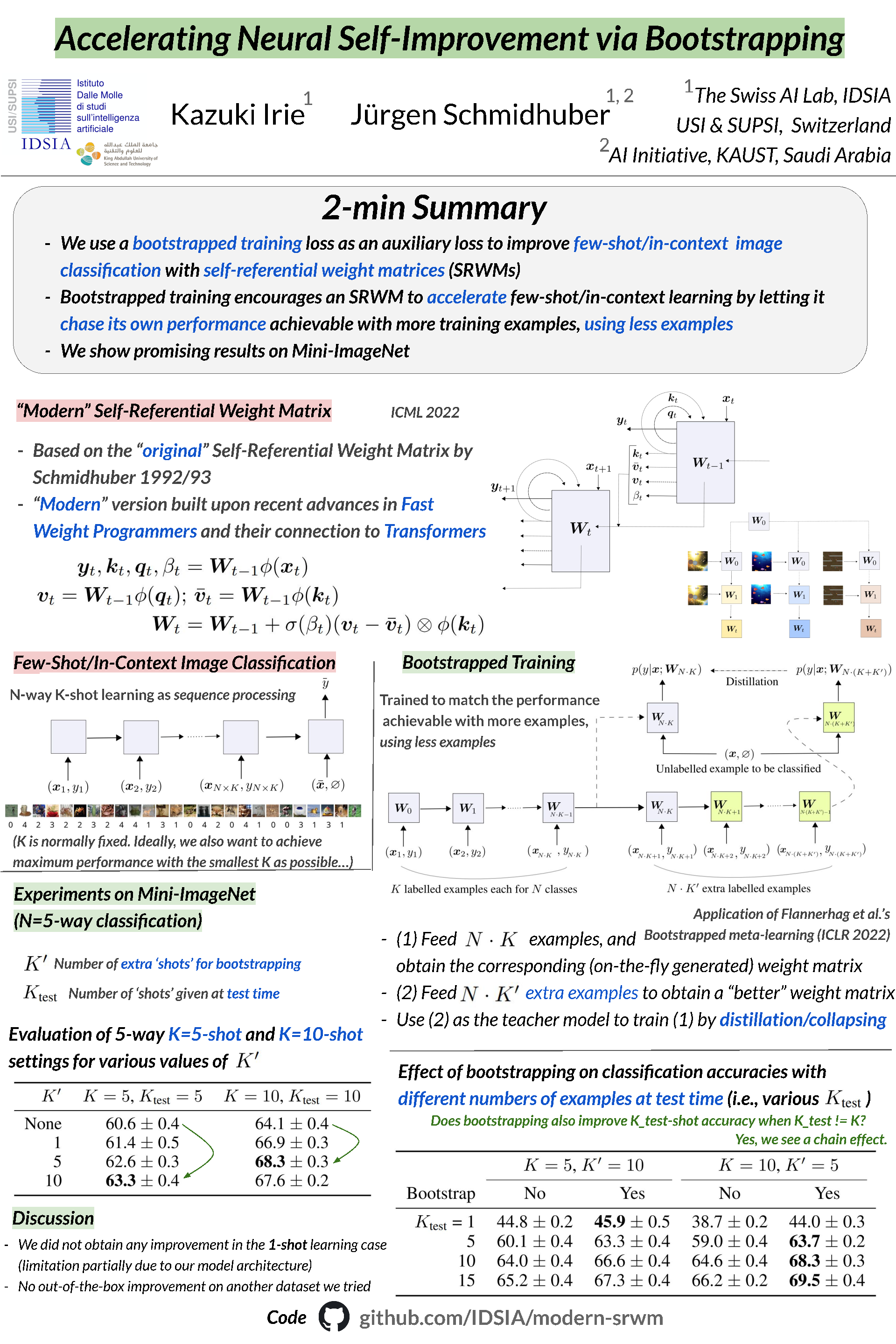
Few-shot learning with sequence-processing neural networks (NNs) has recently attracted a new wave of attention in the context of large language models. In the standard N-way K-shot learning setting, an NN is explicitly optimised to learn to classify unlabelled inputs by observing a sequence of NK labelled examples. This pressures the NN to learn a learning algorithm that achieves maximum performance, given the limited number of training examples. Here we study an auxiliary loss that encourages further acceleration of few-shot learning, by applying recently proposed bootstrapped meta-learning to NN few-shot learners: we optimise the K-shot learner to match its own performance achievable by observing more than NK examples, using only NK examples. Promising results are obtained on the standard Mini-ImageNet dataset.