Bayesian Oracle for bounding information gain in neural encoding models
Konstantin-Klemens Lurz ⋅ Mohammad Bashiri ⋅ Edgar Walker ⋅ Fabian Sinz
Keywords:
neuroscience
information theory
bayesian
evaluation metrics
encoding models
Neuroscience and Cognitive Science
2023 In-Person Poster presentation / poster accept
{kind=link}
Abstract
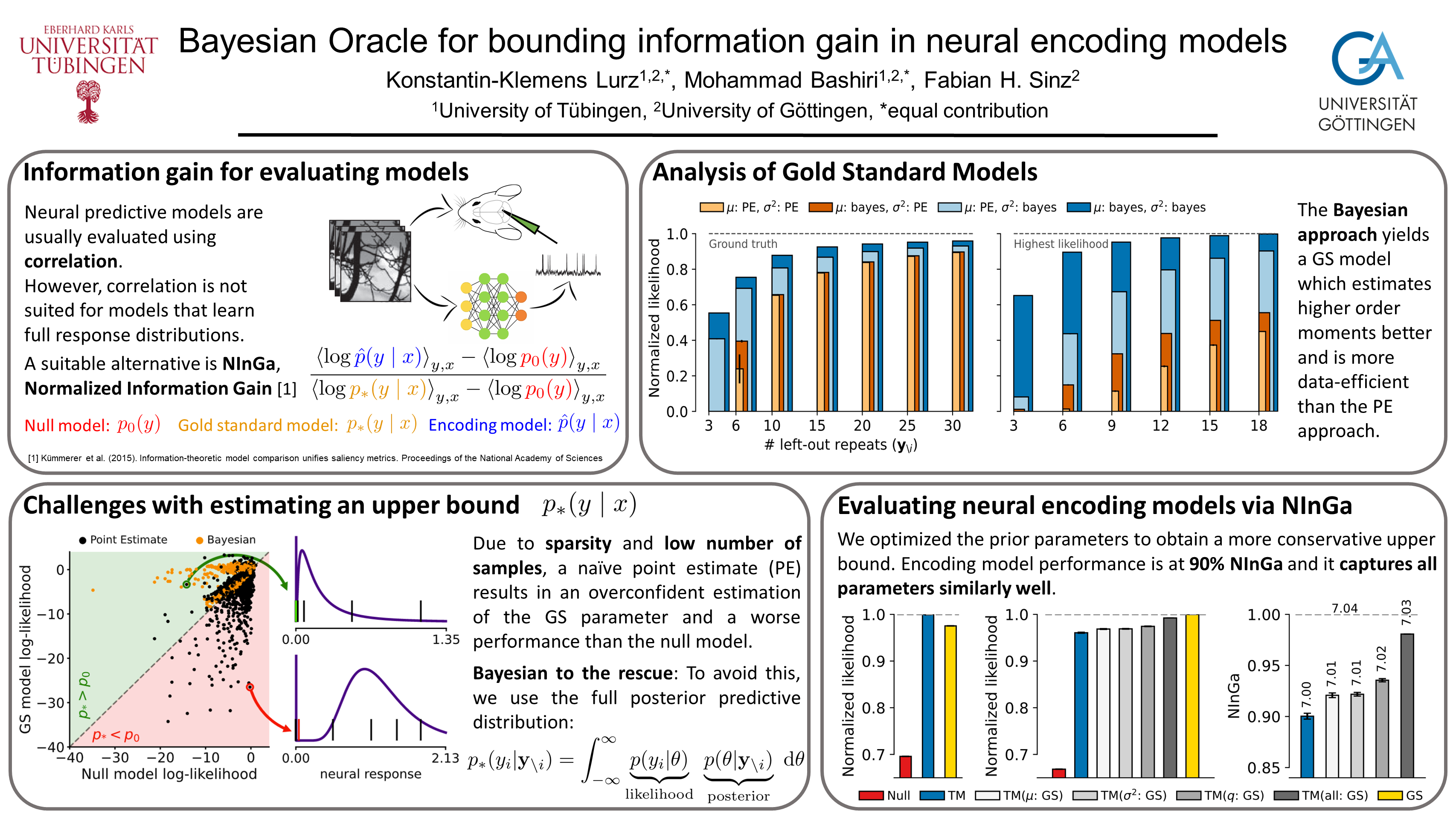
In recent years, deep learning models have set new standards in predicting neural population responses. Most of these models currently focus on predicting the mean response of each neuron for a given input. However, neural variability around this mean is not just noise and plays a central role in several theories on neural computation. To capture this variability, we need models that predict full response distributions for a given stimulus. However, to measure the quality of such models, commonly used correlation-based metrics are not sufficient as they mainly care about the mean of the response distribution. An interpretable alternative evaluation metric for likelihood-based models is \textit{Information Gain} (IG) which evaluates the likelihood of a model relative to a lower and upper bound. However, while a lower bound is usually easy to obtain, constructing an upper bound turns out to be challenging for neural recordings with relatively low numbers of repeated trials, high (shared) variability, and sparse responses. In this work, we generalize the jack-knife oracle estimator for the mean---commonly used for correlation metrics---to a flexible Bayesian oracle estimator for IG based on posterior predictive distributions. We describe and address the challenges that arise when estimating the lower and upper bounds from small datasets. We then show that our upper bound estimate is data-efficient and robust even in the case of sparse responses and low signal-to-noise ratio. We further provide the derivation of the upper bound estimator for a variety of common distributions including the state-of-the-art zero-inflated mixture models, and relate IG to common mean-based metrics. Finally, we use our approach to evaluate such a mixture model resulting in $90\%$ IG performance.
Video
Chat is not available.
Successful Page Load