Relative representations enable zero-shot latent space communication
{kind=link}
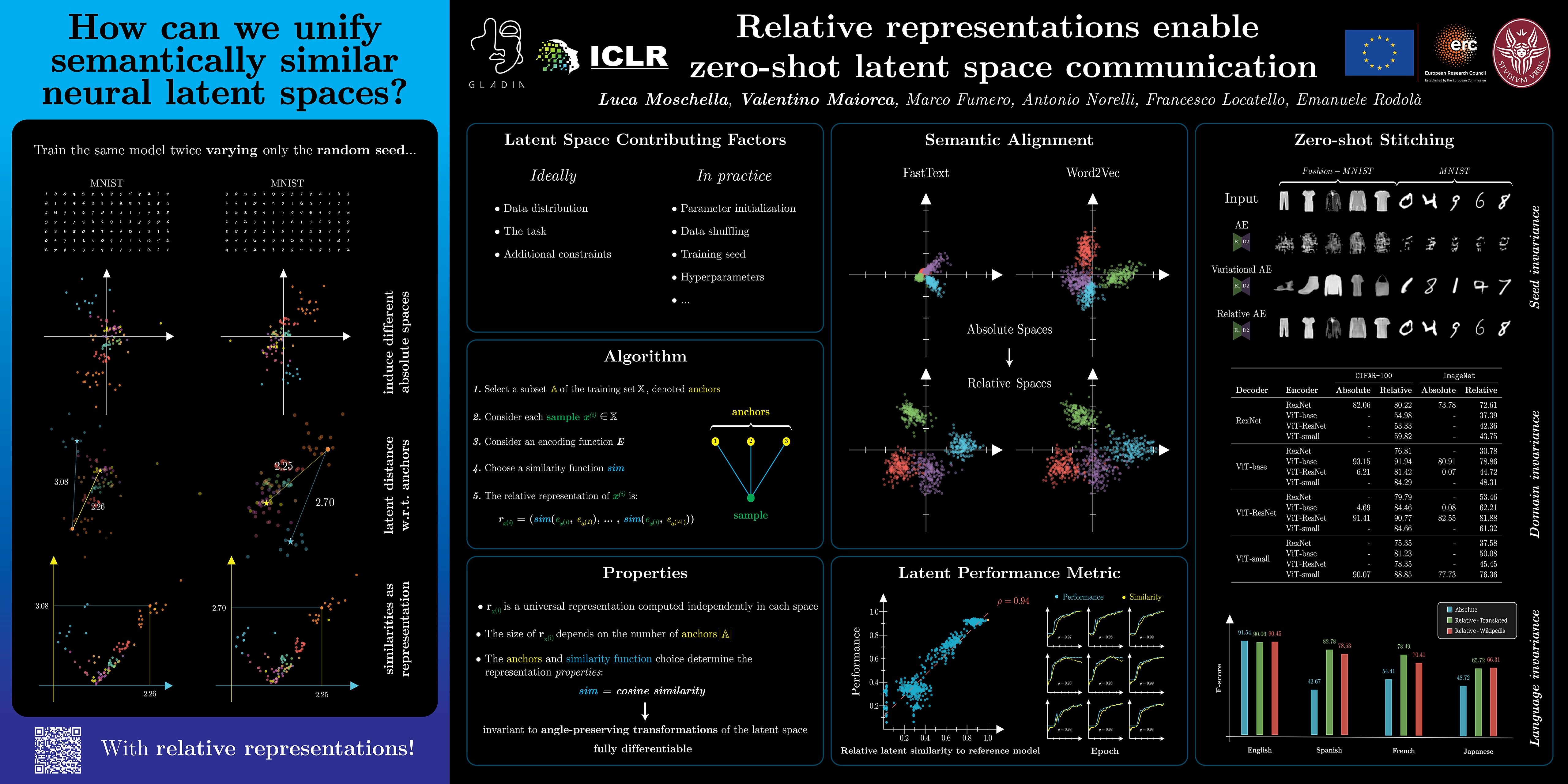
Abstract
Neural networks embed the geometric structure of a data manifold lying in a high-dimensional space into latent representations. Ideally, the distribution of the data points in the latent space should depend only on the task, the data, the loss, and other architecture-specific constraints. However, factors such as the random weights initialization, training hyperparameters, or other sources of randomness in the training phase may induce incoherent latent spaces that hinder any form of reuse. Nevertheless, we empirically observe that, under the same data and modeling choices, the angles between the encodings within distinct latent spaces do not change. In this work, we propose the latent similarity between each sample and a fixed set of anchors as an alternative data representation, demonstrating that it can enforce the desired invariances without any additional training. We show how neural architectures can leverage these relative representations to guarantee, in practice, invariance to latent isometries and rescalings, effectively enabling latent space communication: from zero-shot model stitching to latent space comparison between diverse settings. We extensively validate the generalization capability of our approach on different datasets, spanning various modalities (images, text, graphs), tasks (e.g., classification, reconstruction) and architectures (e.g., CNNs, GCNs, transformers).