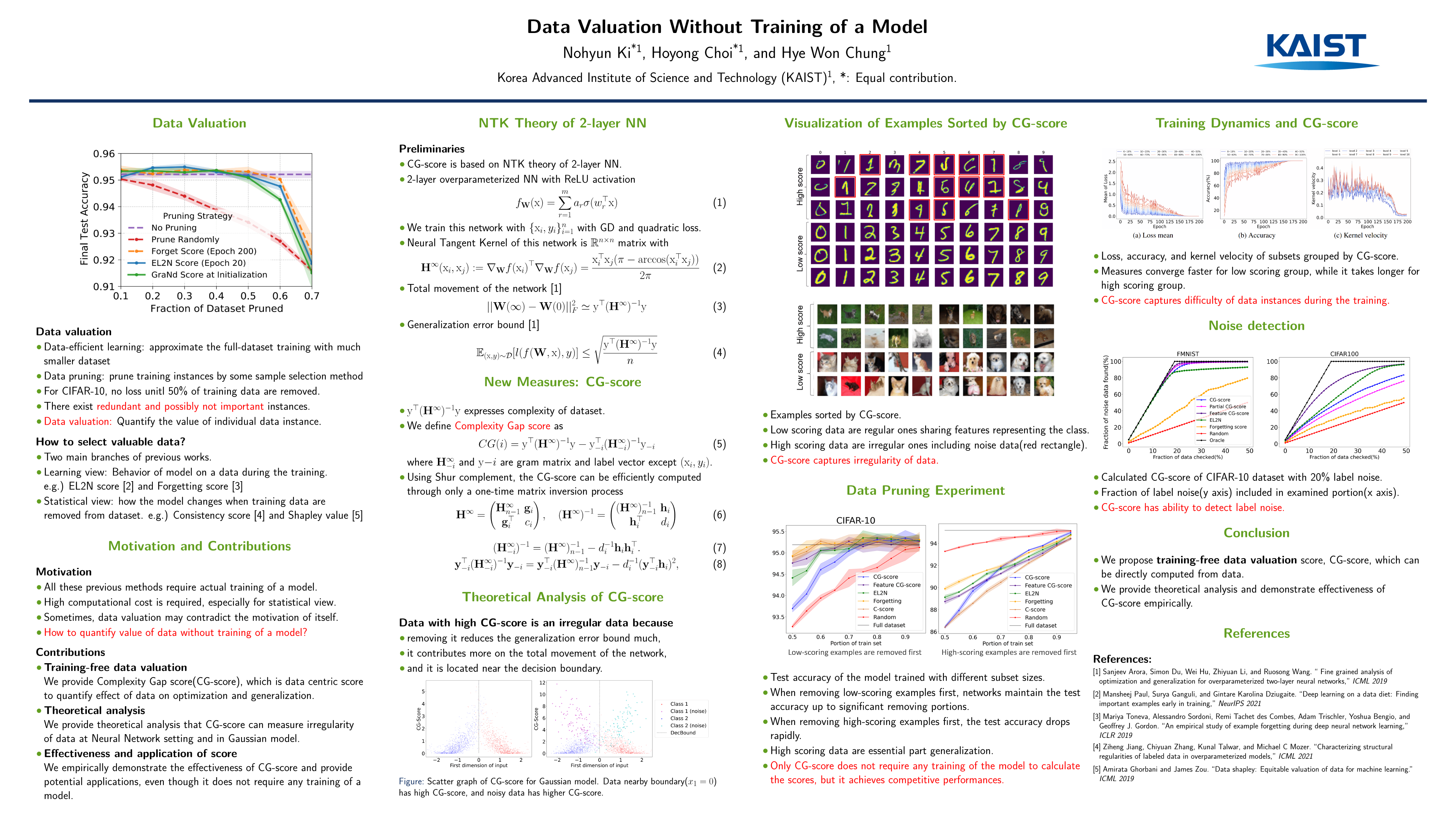
Data Valuation Without Training of a Model
{kind=link}
Abstract
Many recent works on understanding deep learning try to quantify how much individual data instances influence the optimization and generalization of a model. Such attempts reveal characteristics and importance of individual instances, which may provide useful information in diagnosing and improving deep learning. However, most of the existing works on data valuation require actual training of a model, which often demands high-computational cost. In this paper, we provide a training-free data valuation score, called complexity-gap score, which is a data-centric score to quantify the influence of individual instances in generalization of two-layer overparameterized neural networks. The proposed score can quantify irregularity of the instances and measure how much each data instance contributes in the total movement of the network parameters during training. We theoretically analyze and empirically demonstrate the effectiveness of the complexity-gap score in finding `irregular or mislabeled' data instances, and also provide applications of the score in analyzing datasets and diagnosing training dynamics. Our code is publicly available at https://github.com/JJchy/CG_score.