Bit-Pruning: A Sparse Multiplication-Less Dot-Product
Yusuke Sekikawa ⋅ Shingo Yashima
Keywords:
2bit
power of two
non-uniform quantization
pruning
Deep Learning and representational learning
2023 In-Person Poster presentation / poster accept
{kind=link}
Abstract
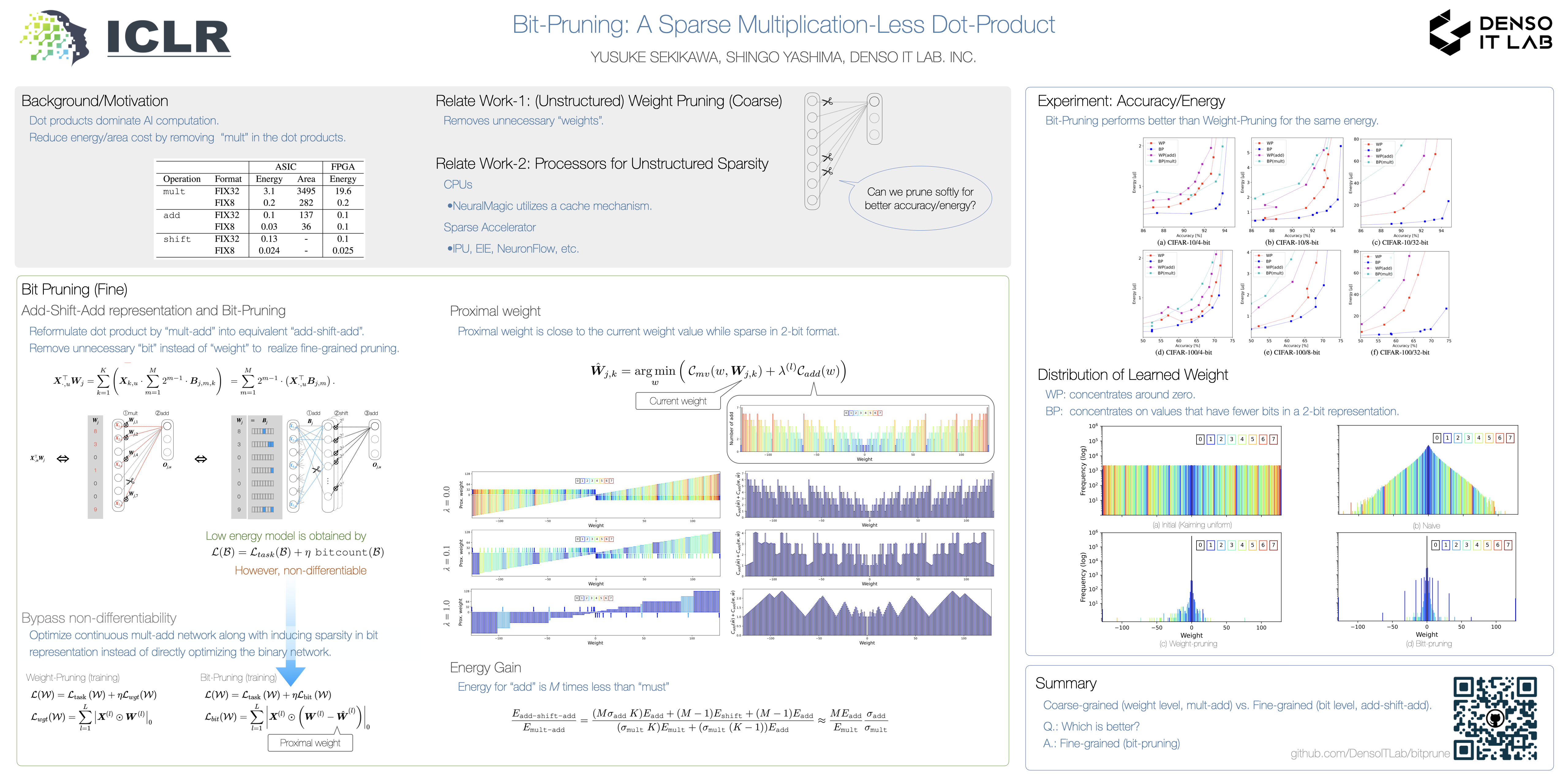
Dot-product is a central building block in neural networks.However, multiplication ($\texttt{mult}$) in dot-product consumes intensive energy and space costs that challenge deployment on resource-constrained edge devices.In this study, we realize energy-efficient neural networks by exploiting a $\texttt{mult}$-less, sparse dot-product. We first reformulate a dot-product between an integer weight and activation into an equivalent operation comprised of additions followed by bit-shifts ($\texttt{add-shift-add}$).In this formulation, the number of $\texttt{add}$ operations equals the number of bits of the integer weight in binary format. Leveraging this observation, we propose Bit-Pruning, which removes unnecessary bits in each weight value during training to reduce the energy consumption of $\texttt{add-shift-add}$. Bit-Pruning can be seen as soft Weight-Pruning as it prunes bits, not the whole weight element.In extensive experiments, we demonstrate that sparse $\texttt{mult}$-less networks trained with Bit-Pruning show a better accuracy-energy trade-off than sparse $\texttt{mult}$ networks trained with Weight-Pruning.
Video
Chat is not available.
Successful Page Load