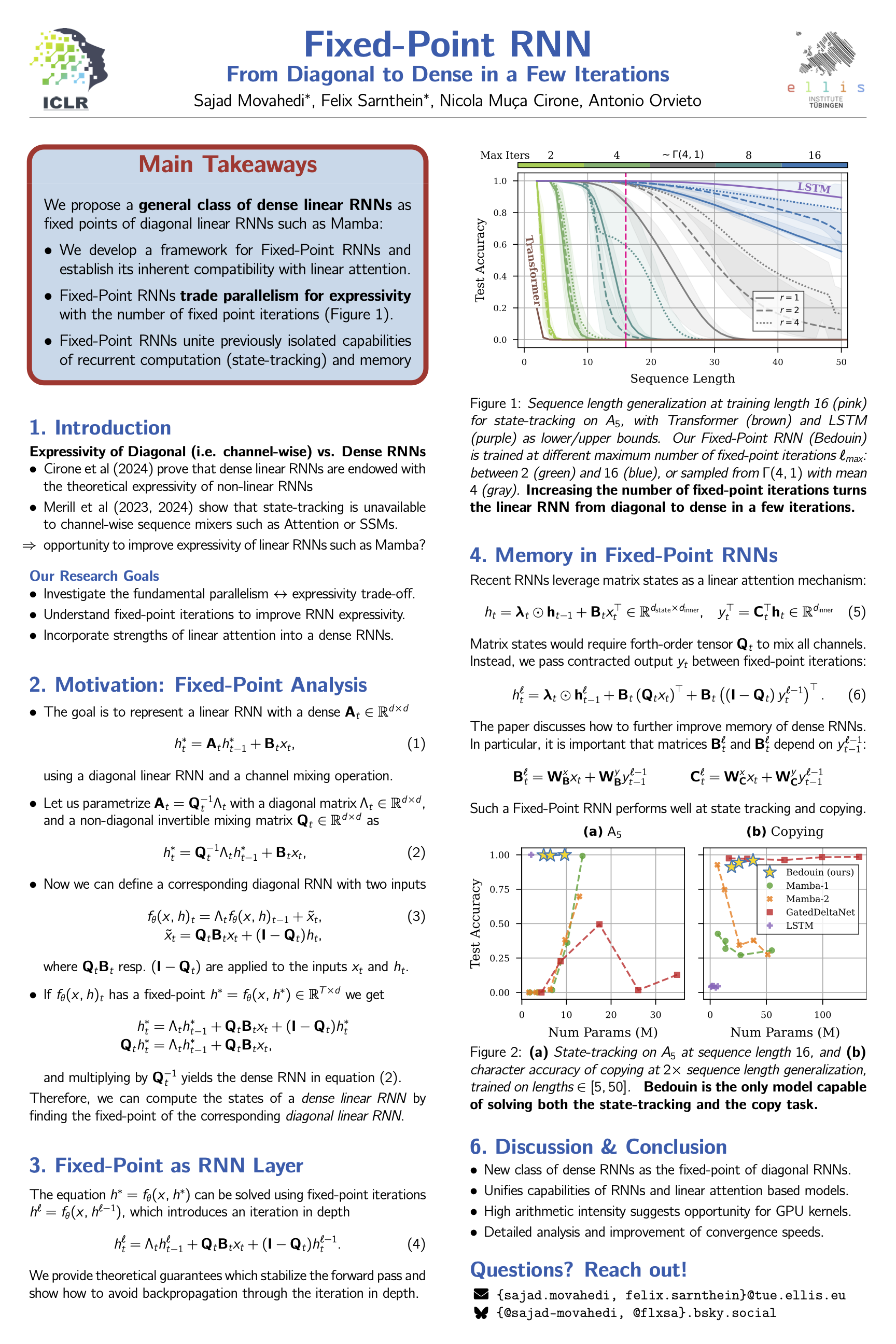
Fixed-Point RNNs: From Diagonal to Dense in a Few Iterations
{kind=link}
Abstract
Linear recurrent neural networks (RNNs) and state-space models (SSMs) such as Mamba have become promising alternatives to softmax-attention as sequence mixing layers in Transformer architectures. Current models, however, do not exhibit the full state-tracking expressivity of RNNs because they rely on channel-wise (i.e. diagonal) sequence mixing. In this paper, we propose to compute a dense linear RNN as the fixed-point of a parallelizable diagonal linear RNN in a single layer. We explore mechanisms to improve its recall and state-tracking abilities in practice, and achieve state-of-the-art results on previously introduced toy tasks such as A5, copying, and modular arithmetic. We hope our results will open new avenues to more expressive and efficient sequence mixers.