Pre-training of Foundation Adapters for LLM Fine-tuning
{kind=link}
Abstract
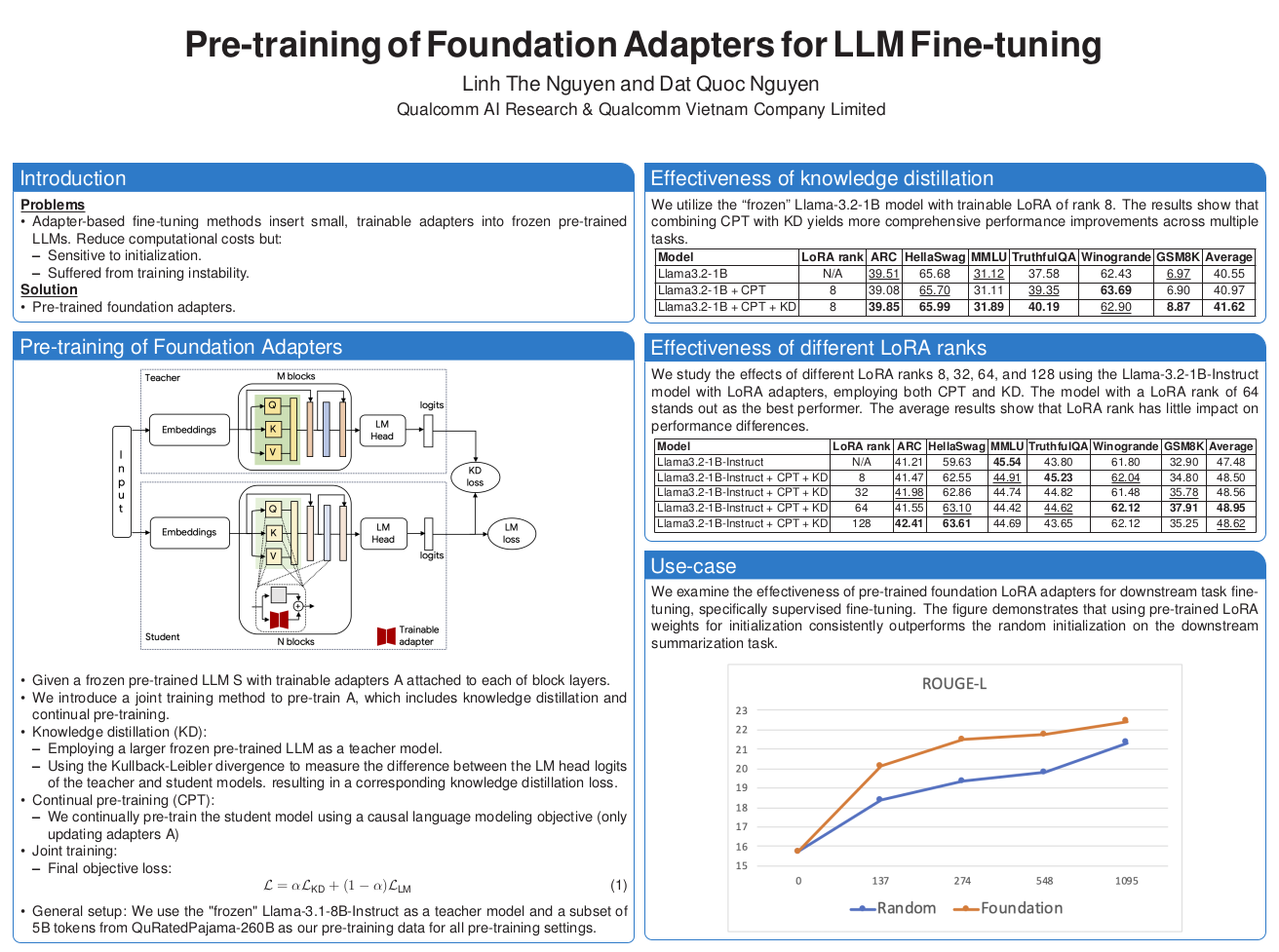
Adapter-based fine-tuning methods insert small, trainable adapters into frozen pre-trained LLMs, significantly reducing computational costs while maintaining performance. However, despite these advantages, traditional adapter fine-tuning suffers from training instability due to random weight initialization. This instability can lead to inconsistent performance across different runs. Therefore, to address this issue, this blog post introduces pre-trained foundation adapters as a technique for weight initialization. This technique potentially improves the efficiency and effectiveness of the fine-tuning process. Specifically, we combine continual pre-training and knowledge distillation to pre-train foundation adapters. Experiments confirm the effectiveness of this approach across multiple tasks. Moreover, we highlight the advantage of using pre-trained foundation adapter weights over random initialization specifically in a summarization task.