A Single Global Merging Suffices: Recovering Centralized Learning Performance in Decentralized Learning
{kind=link}
Abstract
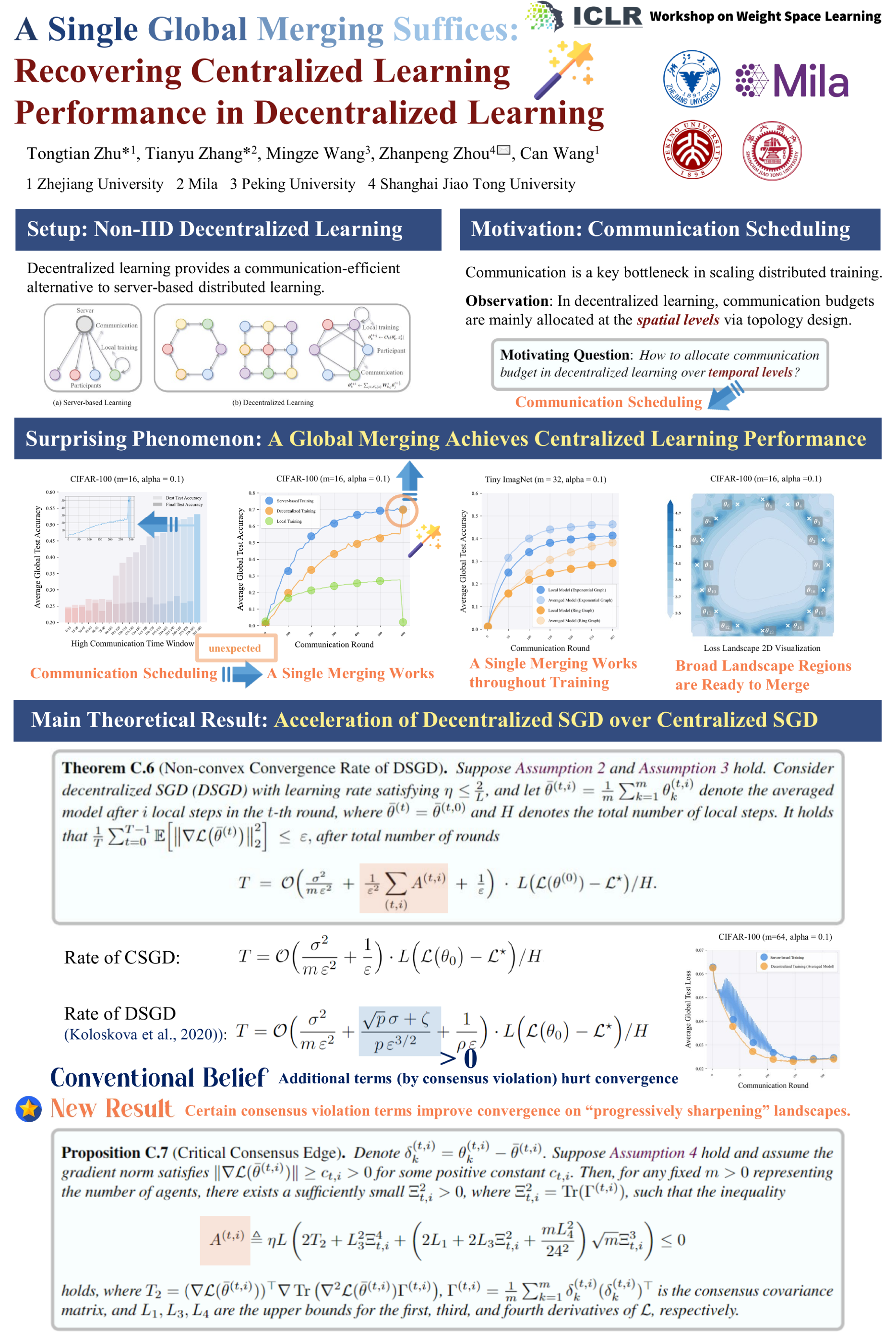
Fully decentralized learning offers a scalable framework for collaborative learning under peer-to-peer communication. A key challenge in this context is how to allocate communication budgets effectively to optimize performance under resource constraints. In this paper, we address this problem and unexpectedly uncover a surprising phenomenon: a single global merging of decentralized models at the final training stage is sufficient to recover performance levels comparable to centralized training, even in highly heterogeneous settings. Crucially, we further observe that minimal communication throughout training enables decentralized models to remain globally mergeable, while models trained entirely locally without communication remain unmergeable. This emphasizes the vital role of sparse communication in decentralized learning. We provide a fine-grained convergence analysis of merged model trained by decentralized SGD (DSGD), demonstrating that it can achieve faster convergence than centralized SGD (CSGD) under certain consensus conditions. The insights from our findings reveal the underestimated capabilities of decentralized learning, showcasing how sparse communication and global merging can unlock its full generalization potential.